notes
總結
CNN 的一些常見設定和介紹
- 捲積層
- 池化層 (Pooling Layer)
CNN 歷史
1986 反向傳播才出來 2006 Hinton 有結果 2012 在語音辨識 爆發性成長 2012 在圖像辨識 爆發性成長
電擊貓的腦袋
發現相鄰神經元有關

且有階層性,初期細胞只能偵測邊,但透過階層性組成就變成能偵測複雜形狀的細胞

以下是常見的影像辨識問題
標記 切割 姿勢識別 RL遊戲 圖像描述的任務 風格生成(Deep Dream) 等等





因為 GPU 能夠大量並行處理,所以才能大幅縮短運算時間
卷積及池化
捲積的過程與介紹
如果是 全連結層(Fully Connected / Dense)
就是將圖片展開成 32 * 32 * 3 (3072) 大小的一維向量後交給 全連結層做計算

但這樣做會喪失像素跟像素間的相對位置訊息
捲積可以保留空間結構訊息 通常是掃過整個色彩通道 3 color channel
 掃過方式的動畫
掃過方式的動畫
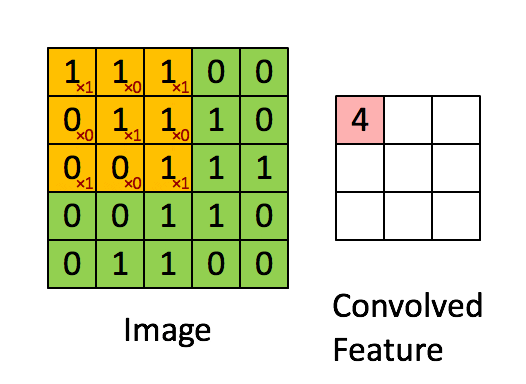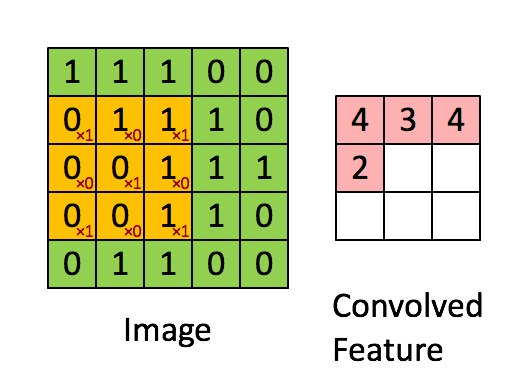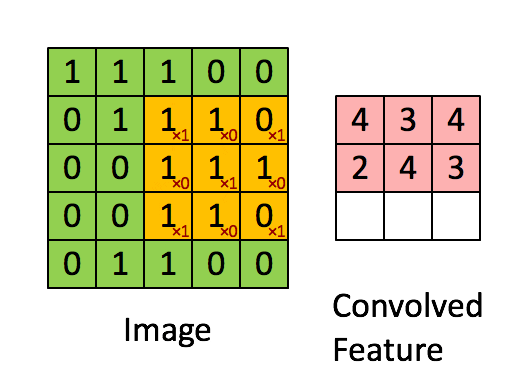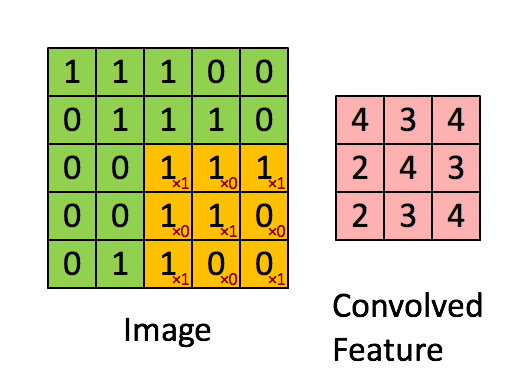
第二層捲積

很多層捲積之後

很多層 捲積層 後

捲基層 只關注圖片的某些部份,而不像 全連接層關注所有的點 這點跟一開始說的神經元很類似
名詞介紹
- filter - 捲積核
- n * n捲基層 (filter) 又可以稱為 n * n 感受(視)野(receptive field),代表 filter 一次看到的範圍是多少
- padding - 填充

- stride - 步伐,即為一次移動多少個 pixel

捲積網路的大概流程
捲積公式(對後面影響不大,看過就好)

捲積過程

視覺化捲積層
透過使神經網路輸出最大值來達到視覺化捲積核 (filter) 的效果 (之後會有更深入的講解)

我們可以發現 前面幾層是 點、線 等簡單特徵, 越後面便是越複雜的特徵, 如 形狀等
參數設定及小技巧
- 盡量讓捲積核可以完全在圖片範圍內,不然可能會有不對稱輸出

- 用 zero padding 填到我們要的大小 也有其他填充方式,例如擴充 or 複製
- 輸出深度就是使用的捲積核的數量(例如有 6 個捲積核,輸出深度就是 6)
- 可以用長寬不同的捲基層(但很少人用)
- 捲積核 通常是 3 * 3 、 5 * 5 、 7 * 7 三種
- 相同大小的不同捲積核作用於相同區域,有著不同功用
學生問題: 為何要有 padding - 為了增加輸出大小 如果輸出快速縮小不太好,因為會損失訊息,只能用很少的訊息表示原始圖像 因此最主要的目的是使輸出不要過快縮小
練習時間


總結 及 常用設定

互動網站
https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
主流深度學習框架的設定
可以參考目前主流深度學習框架裡面的定義 實作 參數
- Torch
- Caffe
Pooling
pooling layer 讓輸出更小,容易控制 就是只做 downsample (降採樣)
pooling 不像 捲積層,要盡量不重疊
max pooling - 常用,效果是 突出 最大的激活數值
Max Pooling

學生問題: 是否可以只有 捲積 或只有 pooling ? 因為都是 downsample 可以,也不少見
常用參數及小技巧
- 通常在深度方向不做池化處理
- 池化層通常不做 zero padding
- 常用 size:
- 2 * 2
- 3 * 3
目前 小尺寸捲積 + 更深的網路是趨勢 完全不用 pooling + FC 也是趨勢(之後說明) 而 ResNet 跟 GoogLeNet 則不是傳統方法
池化層常用設定

參考
https://zhuanlan.zhihu.com/p/31961275 http://cs231n.github.io/convolutional-networks/